개발자를 위한 LLM 엔지니어링- 4. LLM의 학습
이번글에서는 LLM의 학습에 대해서 정리할까 합니다.

이전 글에서 위 그림처럼 LLM은 먼저 모델을 학습하는 과정을 거치고 학습이 완료된 모델을 사용하여 tokenizer 로 입력값을 만들어서 모델에 입력하여 값을 예측하여 사용한다고 했습니다.
그렇다면 맨땅에 모델을 학습하려고 하면 어떤 과정을 거쳐야 할까요? 아마도 아래의 프로세스와 유사하게 진행해야 할것입니다.

먼저 당연히 학습할 데이터를 먼저 준비해야 하고 우리가 학습에 사용할 모델을 선별해야 합니다. 그리고 우리는 pre training 단계로 아무 지식이 없는 백지의 모델을 학습하게 됩니다. 그 다음에는 조금더 도메인에 맞게 fine tuning 이라는 단계를 진행하여 모델을 좀더 학습한 다음에 해당 모델을 배포해서 사용 합니다.
최근에 사용하는 모델들은 transformer 기반의 모델을 사용합니다. 우리가 잘 아는 chatgpt 도 이런 transformer 기반의 GPT 모델입니다. 그리고 오픈소스로 핫한 llama 도 transformer 계열 입니다.
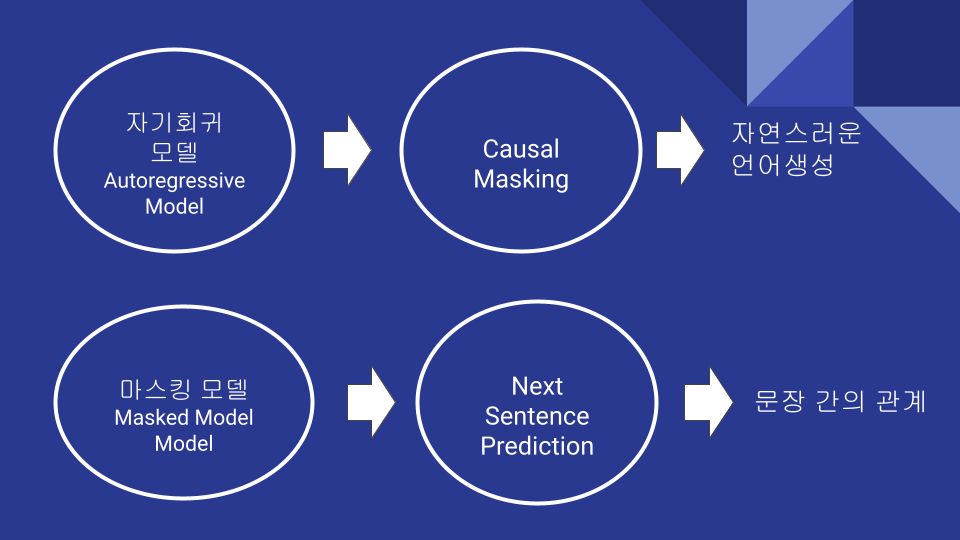
pre training 기법에는 크게 자기회귀 모델 방식과 마스킹 모델 방식이 있습니다.
자기 회귀 모델 방식은 앞에 문장이 주어지면 다음에 올 문장을 예측하는 기법입니다. 예를 들어 The cat is on the mat 를 예측 한다고 가정 하면 The cat 이 주어지면 다음에 나오는 is 를 예측한다고 생각하면 됩니다.
반면에 Masked Models 방식은 The cat [MASK] on the mat 처럼 예측 하고 싶은 부분은 MASK로 가리고 해당 MASK한 부분을 예측 하는 방식입니다.
자기회귀 모델은 좀더 자연스러운 언어 생성에 강점이 있고 Transformer 에서는 Causal Masking 같은 기법으로 이전 문자들만 참조할수 있도록 마스킹 하여 학습을 합니다.
Masked Model 은 문장간의 관계를 파악하는데 더 용이하고 Next Sentence Prediction 처럼 두개의 문장이 연관있는지 체크 하는 task 를 추가하여 학습을 합니다.
pre training 방식은 많은 데이터와 인프라 및 시간이 필요합니다. 그렇기 때문에 일반적인 기업에서는 pre traing 을 할수 없고 대부분 pre traing 한 모델을 fine tuning 하여 사용 합니다. 일반적으로 fine tuning 은 이전에 학습한 pre traing 한 모델의 지식을 이어 받기 때문에 transfer learning(전이 학습) 영역에 속합니다.

대부분 LLM 모델을 학습한다고 하면 fine tuning을 이야기 합니다. fine tuning 은 LLM을 조금더 특정한 작업에 특화 시키기 위해 관련 데이터로 다시 한번 학습을 시킵니다. 이전에는 LLM 모델의 전체 파라미터를 학습하는 full fine tuning 을 사용했지만 LLM 모델이 점점 커져서 full fine tuning 은 사용하지 않고 모델 파라미터의 일부분이나 별도로 추가된 작은 매트릭스만 학습시키는 PEFT(Parameter Efficient Fine Tuning) 방식을 많이 사용합니다. 위 그림에서 full fine tuning 방식 외에는 나머지 방식은 모두 PEFT에 속합니다.
Layer-wise Freezing 방식은 모델 훈련 시 특정 레이어의 파라미터를 고정시키고 일부분만 학습시키는 방식입니다.
Adapter base fine tuning 방식은 별도의 작은 어뎁터를 모듈에 삽입하여 학습 하는 방법입니다.
Prompt tuning 은 입력앞에 별도의 추가 하여 입력에 생성된 Prompt token 을 학습하는 방법 입니다. 이때 Prompt 를 학습 시키는 벡터들만 학습하는 방식 입니다.
Low Rank Adaptation 방식은 Layer-wise Freezing 과 유사하지만 기존의 모델의 파라미터들은 고정하고 별도로 추가한 저차원의 메트릭스를 추가하여 학습하는게 다른 방식입니다.
RLHF는 Reinforcement Learning From Human Feedback 의 약자로 용어 그대로 사전 학습한 모델이 여러 출력을 생성하고 인간이 평가한 데이터를 바탕으로 보상 모델을 학습하여 강화 학습으로 모델을 세밀하게 최적화 하는 방법입니다.
위와 같은 방식으로 fine tuning 까지 학습이 완료된 모델은 사용하는 서비스에 배포하여 입력을 받아서 사용할수 있습니다. 배포할 경우 Prompt Engineering 을 통하여 동작을 제어할수 있습니다. 사실은 이전 fine tuning 까지는 개발자의 영역이라기 보다 데이터 사이언스에 영역에 가까웠습니다.
Prompt Engineering 의 등장으로 개발자가 AI 를 직접 핸들링 할수 있도록 바꾸어 주었다고 해도 과언이 아닙니다.
Prompt Engineering 의 기본은 in-context learning 에 입니다. 모델에 예시를 주면 그거와 유사한 입력이 들어왔을때 알아서 원하는 결과를 나타내게 하는 기술 입니다. 또한 instruction tuning 된 모델과 함께 조합하여 개발자는 프롬프트를 통해서 모델에 원하는 동작을 요구하여 실행 시킬수 있습니다.