개발자를 위한 LLM 엔지니어링- 3. LLM의 동작 tokenizer
이전글에는 LLM 동작에 대한 아주 기초적인 학습 개념에 대해서 작성했었습니다. 이번글에서는 한단계 더 들어가서 실제로 LLM 이 데이터를 어떻게 인식하고 처리하는지에 대한 파이프라인을 살펴보겠습니다.
결국은 LLM도 컴퓨터가 처리하는 것이기 때문에 입력 받는 문자열을 수치화 하여 입력을 해야 합니다.
LLM에 원하는 입력을 하기 위해서는 데이터 전처리 단계가 필요하며 이 전처리가 끝나면 수치값으로 변환 됩니다.
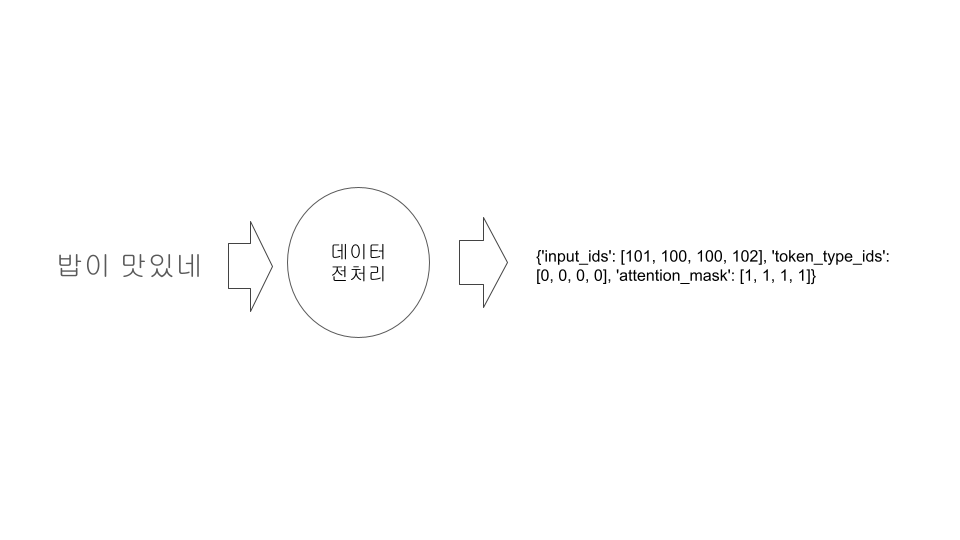
위처럼 문장을 데이터 전처리를 하여 수치화로 변환하는 작업은 tokenizer 가 진행 합니다.
이런 tokenizer 는 다시 정규화 -> 사전토큰화 -> 학습 -> 사후처리 프로세스로 구분됩니다.
정규화 단계에서는 공백 제거, 소문자 변환 및 악센트 제거 등과 같이 문자열의 일반적인 정제 작업을 진행합니다.
사전토큰화 작업은 문자열을 단어와 같은 작은 단위의 토큰으로 분할 합니다.
학습은 tokenizer 가 더욱더 정확해지기 위해 토큰을 병합하거나 규칙을 학습하고 서브워드로 집학을 생성하여 새로운 토큰을 생성하는 등의 학습하는 과정입니다.
사후처리는 tokenizer 모델에서 학습하여 수치한 값에 시작 특수문자나 끝문자 추가 같은 별도의 기능을 첨부하는 단계 입니다.
주의 할것은 이런 tokenizer 의 프로세시는 tokenizer 의 종류에 따라 결과 값이 차이가 난다는 것입니다.
예를 들어 아래는 tokeinzer 의 모델에 따라 정규화 결과의 차이를 나타냅니다.
Héllò hôw are ü? -> hello how are u? (bert-base-uncased)
Héllò hôw are ü? -> Héllò hôw are ü? (bert-base-cased)
위 같이 첫번째 경우는 bert-base-uncased 모델을 사용한 예로 엑센트가 사라지고 대문자가 모두 소문자로 변경된것을 확인 할수 있습니다. 하지만 bert-base-cased 는 엑센트나 대소문자가 변화지 않은것을 확인 할수 있습니다.
tokenizer 의 여러 종류가 있지만 크게 단어기반 , 문자기반, N-Gram, 하위 단어 (subword) 방식의 토큰화로 구분 할수 있습니다.
단어 기반 토큰화는 용어 그대로 단어기반으로 토큰을 구분하는 방식입니다. 일반적으로 공백이나 구두점으로 단어를 구분하여 토큰을 분리할수 있습니다.
Nice to meet you, this is Akun. -> [1: 'Nice', 2: 'to', 3: 'meet', 4: 'you', 5: 'this', 6: 'is', 7: 'AKun']
하지만 한글과 같은 언어는 공백이나 구두점만 가지고는 단어를 구분하기 어려워 형태소 분석기 같은 별도의 도구를 사용하는게 좋습니다.
문자 기반은 텍스트를 단어 기반의 토큰으로 구분으로 하는 방식입니다.
'abcdef' -> [1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e', 6: 'f']
단어 기반의 방식이나 문자 기반의 방식은 텍스트를 토큰으로 구분하고 이를 vocabulary 로 구성하여 토큰의 식별 ID 를 vocabulary 크기만큼 할당 합니다. 단어 기반의 방식에서 방식에 따라서 'dog' 와 'dogs' 는 개별적인 단어가 될수 있고 이는 vocabulary 사이즈를 키우는 문제가 발생 합니다. 또한 vocabulary 에 없는 단어는 id 값을 식별 못하여 인식을 못합니다. 문자 기반은 단어 기반 보다는 out of vocabulary 가 나올 확률이 적지만 토큰 들의 의미를 파악하기 힘듭니다.
N-Gram 방식은 연속된 N개의 문자나 단어를 하나의 토큰으로 취급합니다. 예를 들어 2-Gram 방식은 문자 혹은 단어 2개로 토큰을 구성합니다.
Nice to meet you, this is Akun. -> [1: 'Nice to', 2: 'to meet', 3: 'meet you', 4: 'you this', 5: 'this is', 6: 'is AKun']
하위 단어 토큰화는 빈번하게 사용하는 단어는 덜 분할하고, 희귀 단어들은 하위단어로 분할 하는 방식으로 진행 합니다. 이런 방식은 어휘 다양성과 휘귀 단어의 변형을 효과적으로 처리하여 out of vocabulary 를 상당히 개선해 줍니다.
최근에는 하위 단어 토큰화 방식을 많이 사용하고 대표적인 종류는 아래와 같습니다.
- BPE (Byte Pair Enccoding), Byte-Level BPE
단어를 더 작은 조각으로 분할하여 자주 등장하는 문자쌍을 반복적으로 병합하여 빈도를 기준으로 새로운 단어를 생성
Byte-Level BPE 는 byte 단위로 병합
- wordPiece
단어를 더 작은 조각으로 분할하여 병합시 전체 단어의 우도를 고려하여 병합
- SentencePiece
구글에서 개발한 하위단어(BPE, unigram, 단어, 문자 기반) 토큰화 라이브러리, 사전 토큰화 없이 원시 텍스트를 직접 학습
- Unigram
단어를 더 작은 단위로 분할하여 발생할 loss를 계산 하고, 손실에 가장 적은 영향을 미치는 토큰을 제거, 원하는 어휘 크기에 도달할 때까지 지 반복
BERT 모델에서는 WordPiece 방식을 변형 하여 사용하고 있고 GPT 모델 계열은 BPE 기반을 사용하는 것으로 알고 있습니다.
tokenizer 은 학습 과정을 완료 하면 문자열을 입력받아 token 으로 분리하여 해당 token 들을 고유하게 인식하고 id를 부여하여 수치화 할 하여 LLM에서 필요한 입력 값 형태로 변환 됩니다.
조금더 tokenizer 에 대해서 살펴 보실 분들은 아래부분에 작성한 참고 링크들을 보시면 좋을듯 합니다.
참고 링크:
BPE 소스코드 : https://martinlwx.github.io/en/the-bpe-tokenizer/
BYTE LEVEL BPE : https://github.com/karpathy/minbpe
SentencePiece : https://github.com/google/sentencepiece
unigram tokenization : https://huggingface.co/learn/nlp-course/chapter6/7?fw=pt