개발자를 위한 LLM 엔지니어링- 2. LLM의 기본 동작
이전글에서는 LLM에 대한 기본적인 개념을 작성했었습니다. 이번글에는 한 걸음 더 나아가서 이런 LLM에 대한 동작 관련하여 작성하겠습니다.
LLM은 결국 언어모델(LM)이라고 했었습니다. 그렇다면 언어모델을 먼저 어떻게 만드는지 알아야 언어 모델의 동작 과정을 더욱 이해를 할 수 있을 것입니다.
대부분의 개발자들은 "입력값" -> "동작 알고리즘" -> "결과값"의 동작 순서에 익숙하며 이해하는데 어려움이 없을 것입니다.
하지만 언어 모델은 조금 다른 개념으로 동작을 진행 합니다. 언어 모델의 동작 개념을 이해하기 위해서는 기계학습(Machine Learning, ML )이라는 것을 이해해야 합니다.
기계학습이란 컴퓨터에게 데이터를 학습시켜서 지능을 학습시키게 하는 방법을 연구하는 분야입니다. 언어모델을 생성할 때 이런 기계학습의 한 분야의 방법으로 생성합니다.

기계학습은 모델을 학습시키는 방법에 따라 지도학습, 비지도학습, 강화 학습으로 구분을 할 수 있습니다.
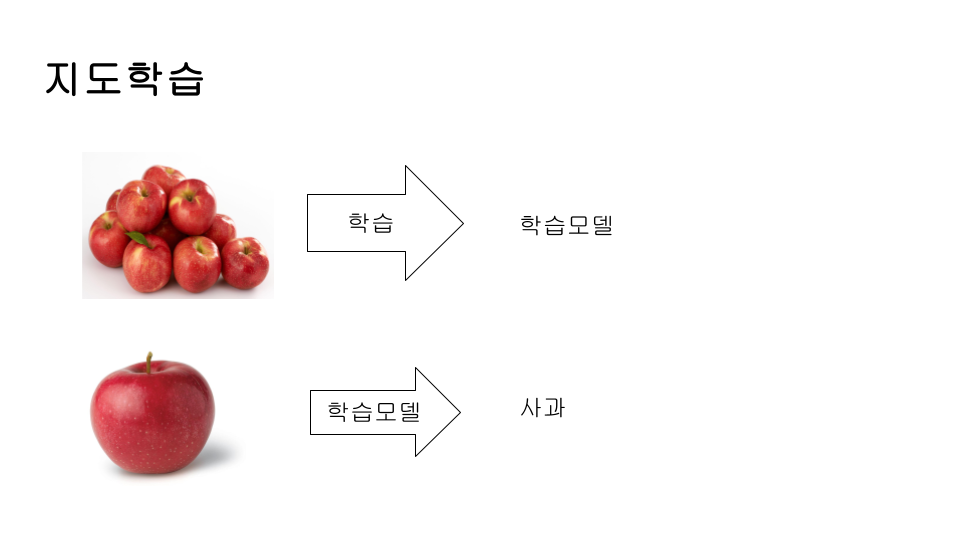
지도학습은 위 그림처럼 모델에 예제와 정답을 알려주고 학습시켜서 학습한 모델이 학습하지 않은 데이터를 입력했을 때 예측하도록 학습하는 방식입니다.

비지도 학습은 모델에 예제만 입력하여 학습시킨 다음에 패턴을 찾아내어 클러스터링을 하거나 생성하는 학습방법을 이야기합니다.

강화 학습은 모델이 예측한 것에 환경과 작용하여 reward를 주어서 다음 행동을 예측하게 학습하는 방식입니다.
최근에 언어 모델은 지도학습, 비지도학습, 강화학습을 혼합하여 학습하는 방식을 사용합니다.

언어모델은 위의 그림처럼 먼저 학습데이터를 이용하여 모델을 학습시킨 후 학습이 완료된 모델을 이용하여 예측하는 작업을 진행합니다. 즉 학습과 예측 프로세스는 구분되어 진행합니다. 학습을 위해서는 많은 데이터와 컴퓨팅 파워 시간이 소요됩니다. 만약 모델의 성능을 변경하고 싶으면 다시 학습해야 합니다. 일반적으로 개발을 진행할 때 로직 작성과는 차이점이 있습니다. 프로그래밍 로직 작성은 비교적 개발자가 적은 비용으로 알고리즘을 수정해 가면서 완성을 하게 됩니다. 그러나 언어 모델은 로직을 디테일하게 변경할 수 없으며 오로지 학습데이터를 변경하거나 정해지 모델구조에서 파라미터를 변경하여 재학습시키는 방법 밖에 없습니다.
이번글에서는 언어모델의 대략적인 학습 개념에 대해서 작성했습니다, 다음 그에서는 실제로 언어 모델에 입력값과 동작 구조에 대해서 좀 더 자세하게 작성하겠습니다.